the Digital Research Alliance of Canada 使用记录
连接 the Digital Research Alliance of Canada
在准备好账户以后,在网站上添加自己的ssh key,然后就可以连接到服务器了。
ssh <your_username>@<server_ip>
这里的server_ip是服务器的ip地址,your_username是你的用户名。server_ip的选择有:
cedar.computecanada.ca
graham.computecanada.ca
beluga.computecanada.ca
应该还有很多其他的选择,但是这里只列出了一些常用的。我尝试过graham服务器,但是发现连接不上,发邮件问了一下,得到的回复是graham服务器的问题,所以我就选择了beluga服务器。
查看资源
查看资源可以使用命令
sinfo --format="%n %P %G"
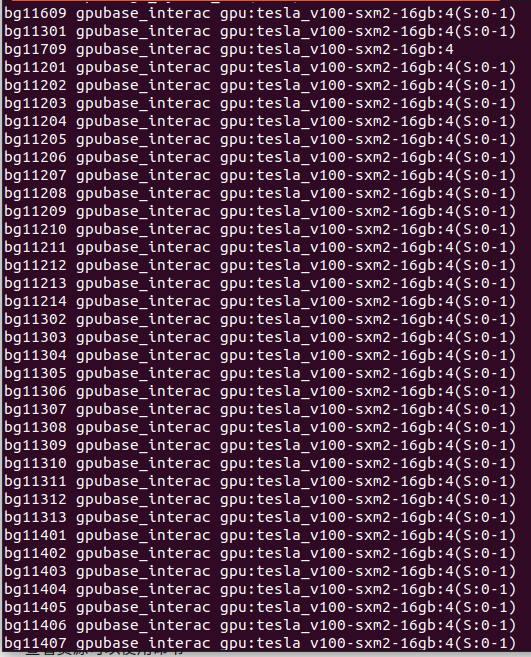
可以看到里面有很多tesla_v100-16g,如果你的任务需要GPU,那么可以选择这种资源。
通过脚本来获取GPU资源:
#!/bin/bash
#SBATCH --job-name=gpu_test
#SBATCH --time=00:30:00 # Max run time
#SBATCH --account=<your_account> # Account name
#SBATCH --partition=gpu # Use the GPU partition
#SBATCH --gres=gpu:1 # Request 1 GPU
#SBATCH --cpus-per-task=4 # Request 4 CPU cores
#SBATCH --mem=16G # Memory allocation
module load python/3.9 cuda/11.7 # Load necessary modules
srun python your_script.py # Run your script
your_script.py是你的脚本。这里的--gres=gpu:1表示请求一个GPU资源,--cpus-per-task=4表示请求4个CPU资源,--mem=16G表示请求16G内存。
如果想要有互动的GPU资源,可以使用命令:
salloc --gres=gpu:1 --time=1:00:00 --mem=16G --cpus-per-task=4
在这里的--time=1:00:00表示请求1小时的时间,--mem=16G表示请求16G内存,--cpus-per-task=4表示请求4个CPU资源。
然后就是安装依赖了,比如我想使用pytorch,那么可以使用命令:
module load python/3.10.3 cuda/12.2
avail_wheels "torch*"
可以查看他们提供的pytorch版本。然后就可以安装了:
pip install --no-index torch
注意这里的--no-index表示不使用pypi源,而是使用他们提供的源。

测试python:
pytorch-test.sh:
#!/bin/bash
#SBATCH --gres=gpu:1 # Request GPU "generic resources"
#SBATCH --cpus-per-task=6 # Cores proportional to GPUs: 6 on Cedar, 16 on Graham.
#SBATCH --mem=32000M # Memory proportional to GPUs: 32000 Cedar, 64000 Graham.
#SBATCH --time=0-03:00 # DD-HH:MM:SS
#SBATCH --output=%N-%j.out
module load python/3.10.13 # Make sure to choose a version that suits your application
virtualenv --no-download $SLURM_TMPDIR/myenv
source $SLURM_TMPDIR/myenv/bin/activate
python pytorch-test.py
pytorch-test.py:
import torch
x = torch.Tensor(5, 3)
print(x)
y = torch.rand(5, 3)
print(y)
# let us run the following only if CUDA is available
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
print(x + y)
else:
raise Exception('CUDA is not available')
然后发现cuda并不能使用。看到官网历程,我使用的是beluga服务器,可能是这个原因对cuda支持并不好,但是我又可以看到gpu资源,所以我不知道是什么原因。
这个是beluga服务器的gpu资源:
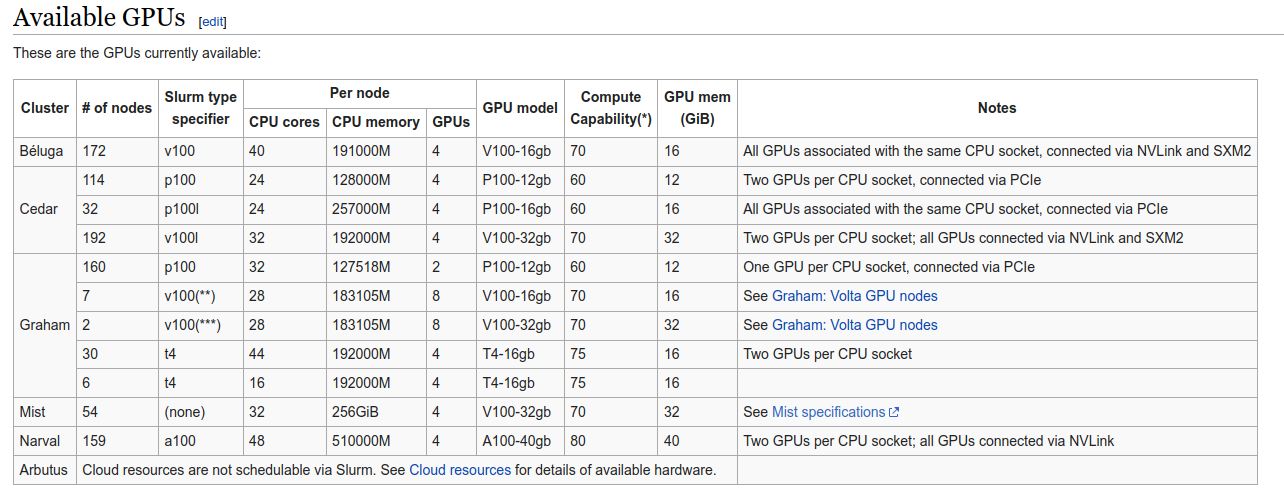
issues
发现这里仍然存在很多问题,比如说配置好服务器环境资源以后,上传任务等待时间过长:
pytorch-ddp-test.sh:
#!/bin/bash
#SBATCH --nodes 1
#SBATCH --gres=gpu:2 # Request 2 GPU "generic resources”.
#SBATCH --tasks-per-node=2 # Request 1 process per GPU. You will get 1 CPU per process by default. Request more CPUs with the "cpus-per-task" parameter to enable multiple data-loader workers to load data in parallel.
#SBATCH --mem=8G
#SBATCH --time=0-03:00
#SBATCH --output=%N-%j.out
module load python # Using Default Python version - Make sure to choose a version that suits your application
srun -N $SLURM_NNODES -n $SLURM_NNODES bash << EOF
virtualenv --no-download $SLURM_TMPDIR/myenv
source $SLURM_TMPDIR/myenv/bin/activate
pip install torchvision --no-index
EOF
export TORCH_NCCL_ASYNC_HANDLING=1
export MASTER_ADDR=$(hostname) #Store the master node’s IP address in the MASTER_ADDR environment variable.
echo "r$SLURM_NODEID master: $MASTER_ADDR"
echo "r$SLURM_NODEID Launching python script"
# The $((SLURM_NTASKS_PER_NODE * SLURM_JOB_NUM_NODES)) variable tells the script how many processes are available for this execution. “srun” executes the script <tasks-per-node * nodes> times
source $SLURM_TMPDIR/myenv/bin/activate
srun python pytorch-ddp-test.py --init_method tcp://$MASTER_ADDR:3456 --world_size $((SLURM_NTASKS_PER_NODE * SLURM_JOB_NUM_NODES)) --batch_size 256
pytorch-ddp-test.py:
import os
import time
import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
import torch.distributed as dist
import torch.utils.data.distributed
import argparse
parser = argparse.ArgumentParser(description='cifar10 classification models, distributed data parallel test')
parser.add_argument('--lr', default=0.1, help='')
parser.add_argument('--batch_size', type=int, default=768, help='')
parser.add_argument('--max_epochs', type=int, default=4, help='')
parser.add_argument('--num_workers', type=int, default=0, help='')
parser.add_argument('--init_method', default='tcp://127.0.0.1:3456', type=str, help='')
parser.add_argument('--dist-backend', default='gloo', type=str, help='')
parser.add_argument('--world_size', default=1, type=int, help='')
parser.add_argument('--distributed', action='store_true', help='')
def main():
print("Starting...")
args = parser.parse_args()
ngpus_per_node = torch.cuda.device_count()
""" This next line is the key to getting DistributedDataParallel working on SLURM:
SLURM_NODEID is 0 or 1 in this example, SLURM_LOCALID is the id of the
current process inside a node and is also 0 or 1 in this example."""
local_rank = int(os.environ.get("SLURM_LOCALID"))
rank = int(os.environ.get("SLURM_NODEID"))*ngpus_per_node + local_rank
current_device = local_rank
torch.cuda.set_device(current_device)
""" this block initializes a process group and initiate communications
between all processes running on all nodes """
print('From Rank: {}, ==> Initializing Process Group...'.format(rank))
#init the process group
dist.init_process_group(backend=args.dist_backend, init_method=args.init_method, world_size=args.world_size, rank=rank)
print("process group ready!")
print('From Rank: {}, ==> Making model..'.format(rank))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[current_device])
print('From Rank: {}, ==> Preparing data..'.format(rank))
transform_train = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset_train = CIFAR10(root='./data', train=True, download=False, transform=transform_train)
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset_train)
train_loader = DataLoader(dataset_train, batch_size=args.batch_size, shuffle=(train_sampler is None), num_workers=args.num_workers, sampler=train_sampler)
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=1e-4)
for epoch in range(args.max_epochs):
train_sampler.set_epoch(epoch)
train(epoch, net, criterion, optimizer, train_loader, rank)
def train(epoch, net, criterion, optimizer, train_loader, train_rank):
train_loss = 0
correct = 0
total = 0
epoch_start = time.time()
for batch_idx, (inputs, targets) in enumerate(train_loader):
start = time.time()
inputs = inputs.cuda()
targets = targets.cuda()
outputs = net(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100 * correct / total
batch_time = time.time() - start
elapse_time = time.time() - epoch_start
elapse_time = datetime.timedelta(seconds=elapse_time)
print("From Rank: {}, Training time {}".format(train_rank, elapse_time))
if __name__=='__main__':
main()
然后发现

等待时间遥遥无期。